Background science for the Turkish mutations, I.
As stories appear in the news about the "small" mutations in the bird flu virus, it's time to do a little background for those of you who want to know a little of what this is all about. For a lot of you this much more than you want to know, but there are a number of lay and professional (but non-specialist) readers of this blog who have become quite knowledgeable and this is meant to provide some additional background. We'll make a stab at it here. Let is know if we are succeeding or failing.
The influenza (or any) virus needs to get inside a host cell in order to make new copies of itself. Reproducing is essentially its only task in life. We know that viruses and other pathogens don't usually infect all animals (they have a specific host range) and within an animal, usually infect only specific tissues. So cells from different animals and different tissues must somehow look different to the virus. How does a virus "recognize" the right cell? This question goes to the heart of the current concern over the small mutations discovered in the Turkish cases. Although we are leaving out a lot of details, there is still much we need to discuss.
Since the virus first "sees" the cell from the outsid, we start at the cell surface or cell membrane, as it's called. Animal cell membranes have a very complicated structure but essentially they consist of a supporting structure, called a lipid bilayer and various bits and pieces sticking on, in and through it. Below is a picture of a lipid bilayer, the structural stuff. (I copped this from a nice set of 1997 lecture notes by Prof. Steve Downing at the University of Minnesota-Duluth. This is copyrighted material, but I am not making any money from it and if the Regents of the University of Minnesota want me to take it down I will, of course. I doubt they care and are probably grateful for the free publicity.)

You can see the reason it's called a bilayer (it has two layers). Each little building block consists of two long fatty chains (the black bars) joined at the end by one of the colored balls. The fatty chains don't like to mix with water and face each other in the interior of the membrane, while the colored balls don't mind water and line both the interior and exterior of the cell. The reason the diagram has different colored balls is that these building blocks can be of various kinds (called phospholipids).
Besides the phopsholipits, there are also a fair number of glycolipids. They aren't shown above because I wanted to keep the picture clean. Whenever you see the word "glyco-" attached to something you should be thinking sugars (carbohydrates). Lots of the building blocks have sugars on them. Attaching a sugar is called glycosylation, and the thing that has the sugar attached is said to be glycosylated (and often the location of the attachment is given). Here's a closer view of a glycolipd, showing some of the molecules (the long CH

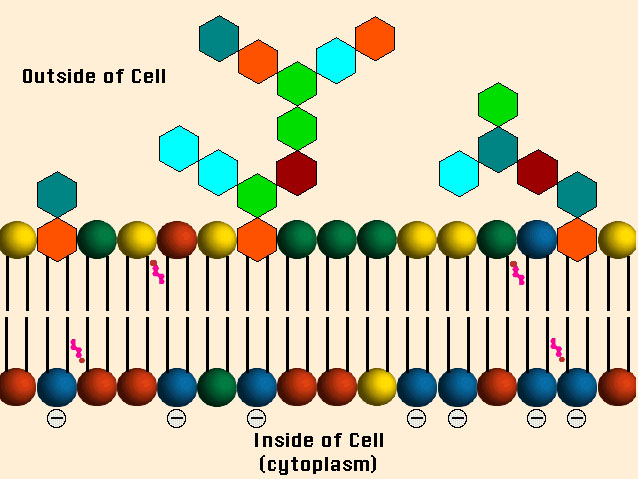

We'll press on with more details in subsequent posts.
posted by Revere at
1/17/2006 05:24:00 AM
![]()
![]()

<< Home